Поражение
Я зарегистрировалась на Kaggle.com в 2015 году, но даже не помнила об этом. В апреле 2019 года перешла на Python, в октябре активировала свой профиль Kaggle и выложила два алгоритма (notebook). Для затравочки, так сказать.
Вот уже 13 лет мои разработки математических моделей посвящены электроэнергетике: процессам выработки, потребления и, главное, торговле электроэнергии на оптовом рынке. Да-да, почти во всех развитых странах функционируют оптовые рынки электричества. На Kaggle почти нет соревнований, посвященных электроэнергетике. Мне удалось найти всего два:
- ASHRAE - Great Energy Predictor III (проводилось в октябре-декабре 2019 года)
- Global Energy Forecasting Competition 2012 - Wind Forecasting (проводилось в 2012 году)
Соревнование ASHRAE шло, люди работали. В рамках соревнования нужно было сделать долгосрочный прогноз потребления 4 видов энергии (электроэнергия, пар, холодная и горячая вода) для 1500 зданий, расположенных на 16 территориях.
После долгих раздумий я ткнула join competition. Почему долгих? Потому что я понимала (со времен соревнования Яндекса по прогнозам пробок в 2010 году), что соревнования требуют колоссальных усилий, времени и упорства. Ткнула… и обалдела! С такими массивами данных в своей сфере мне сталкиваться еще не приходилось:
- Таблица исходных данных ~20M x 16 значений
- Результат вычислений столбец ~42M значений
Приложив, как мне тогда казалось, заметные усилия, чтобы реализовать простую регрессионную модель, мне удалось сделать 15 попыток загрузки результата и занять 2431 место из 3614 участников. Это поражение.
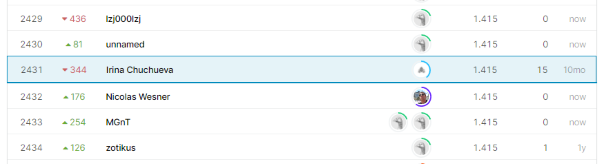
Точнее, мои оценки выглядят так:
- Private Score: 1.415 (2431 место из 3614)
- Public Score: 1.185 (2087 место из 3614)
Работа над ошибками
В начале января 2020 были опубликованы итоговые результаты. Победители поразили меня и своей точностью, и свой открытостью: большинство победителей опубликовали описание своих алгоритмов/моделей. Я выделила день и внимательно прочитала описания основных решений, просмотрела десяток ключевых алгоритмов и поняла: учиться нужно у победителей. Для этого требуется найти время и самостоятельно реализовать алгоритмы, о которых я прочитала. Цель: сделать 200 загрузок и попасть в 10% лучших результатов.
С января по июнь 2020 года я упорно выделяла часы, когда занималась ASHRAE. Основной рывок пришелся на май и начало июня.
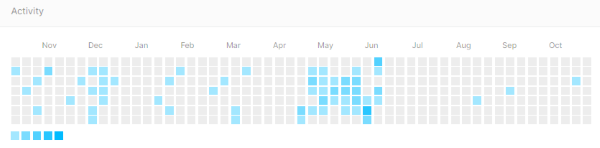
На странице соревнования есть кнопка late submission, которая позволяет загружать прогнозы даже после окончания соревнований. За 5 месяцев мне удалось сделать 158 late submission и добиться результатов, входящих в ~12%. Детали:
- Private Score: 1.291 (558/3614) было 1.415
- Public Score: 0.964 (269/3614) было 1.185

Разработанный фреймворк опубликован на моей git странице. Дальше продвинуться мне не удалось, поскольку в начале июня 2020 начался новый контракт и работы стало много. На сегодняшний день в моих планах задача ASHRAE отсутствует.
Урок 1: учиться нужно у лучших
Соревнование ASHRAE стало для меня издевательством над собой. Важным и полезным. После 12 лет работы в области разработки математических моделей для решения задач планирования и прогнозирования на оптовом рынке электроэнергии и мощности России я думала о себе высоко. За плечами несколько крупных успешно реализованных проектов, кандидатская диссертация в области математического моделирования, высокая зарплата, популярный блог, впечатляющая научная цитируемость и т.д. и т.п.
Соревнование ASHRAE вернуло меня с небес на землю: сотни людей, многие из которых впервые сталкиваются с задачей прогнозирования потребления энергии, не имеют и трети моих регалий, получили решение соревновательной задачи быстрее и точнее.
Пока я делала работу над ошибками, мне было тяжело, больно, хотелось бросить. Публикую кусочек из своего июньского письма моему другу профессору МГТУ им. Н.Э. Баумана А.П. Карпенко.
Предметная область моя, при этом очень большой объем данных, практически нереально все это глазами просматривать. По итогам моих работ в ноябре-декабре у моих «жиденьких» попыток был такой же «жиденький» результат. Но я не плюнула, попереживала, решила, что я доделаю свой фреймворк и получу приличные баллы. Сначала совсем ничего не получалось и ощущала себя полным нулем. Будто я ничего не знаю! Ощущение ужасное. С 12-летним опытом работы в этой области вдруг почувствовала себя дилетантом. Это был ужас! Ужас! Но я работала дальше, тяжело и противно, но дальше. Где-то после 50 загрузки у меня начинало просыпаться ощущение «получается». Это дает воздух внутри, дает надежду! В итоге я сделала 158 загрузок, стараясь в каждом своем шаге быть предельно последовательной и внимательной. По крайней мере для половины загрузок мои ожидания расходились с реальностью. Когда это случалось, опускались руки. Переживала, через час говорила себе: «Я неправильно понимала, оттого были неправильные ожидания, нужно корректировать их, учиться. Если мне так паршиво, значит, я учусь».
Талантливые ребята, опытные кагглеры, грозные команды-победители — словом, самые квалифицированные и смелые участники ASHRAE заставили меня начать с начала: почувствовать себя бестолковым первокурсником, смотреть на их работы как на методичку, думать, повторять, оценивать и добиваться приличных результатов. Это был самый отрезвляющий проект в моей профессиональной жизни.
Урок 2: data scientist должен уметь работать с множеством моделей
В рамках соревнования ASHRAE я впервые услышала о таких библиотеках, как LightGBM, CatBoost, Prophet. Про XGBoost я слышала раньше, но не имела опыта работы с этой библиотекой. Регрессию и Neural Network (Python/Keras/TensorFlow) я знала и использовала давно.
Так выглядит структура решения команды, занявшей второе место. Site обозначает территорию.
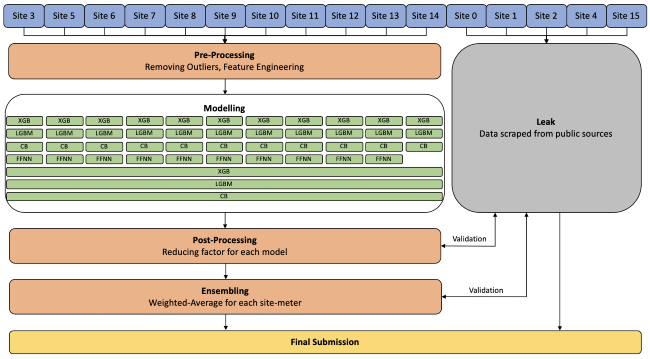
XGB: XGBoost
LGBM: LightGBM
CB: CatBoost
FFNN: Feed-forward Neural Network
Моя любимая команда, занявшая второе место, подробно описала решение: они создали около 20К моделей (да-да, 20 000 моделей!) и смешали их результаты. На Kaggle я узнала, что процесс смешивания или ансамблирования моделей называют блендинг (blending). Чтобы получить максимальный эффект от блендинга, нужны модели, с одной стороны, сопоставимого качества; с другой — обладающие важными отличиями и добавляющие разнообразия (diversity) в такую солянку. Разнообразие достигается в том числе за счет использования различных библиотек. Этим прекрасен Python: для него доступен грандиозный арсенал открытых математических библиотек. Насколько я поняла, невозможно выиграть соревнование на Kaggle без батареи точных моделей, грамотно сбленденных между собой.
Блендинг может быть организован как довольно просто и для каждой модели используют фиксированный (экспертом определенный) числовой коэффициент, так и сложно — для вычисления коэффициентов решают задачу оптимизации.
В моей работе мне редко удается сконцентрироваться надолго на одной математике и, как я называю, «жонглировать цифрами» с целью получения максимальной точности. Примерно половина моей работы состоит в понимании и описании предметной области, вторая половина в прикручивании математики к этой предметной области. Соревнования Kaggle дают возможность получить этот недостающий, но важный профессиональный опыт «жонглирования», который позволит эффективнее делать вторую половину моей работы. Теперь, кроме регрессии и Neural Network, в моем арсенале появились «wonder boostings» (LightGBM, CatBoost, XGBoost). Впечатления от работы с фейсбучным Prophet остались гадкими.
Мой результат ~12% является прогнозом, полученным как арифметическое среднее 3-х наборов: первый набор содержит 56 моделей LightGBM, обученных по территориям; второй — 24 модели LightGBM, обученных по видам энергии; третий — 36 моделей XGBoost, обученных по территориям. Предварительная обработка (preprocessing): линейная интерполяция погодных данных, удаление постоянных значений (constant) из значений энергии для заданного списка зданий. Постобработка (postprocessing) отсутствует. Выглядит довольно просто, не так ли? Сравнив схему победителей и мои наработки, становится очевидным, каким образом мой результат следует улучшать.
Урок 3: экстенсивный опыт неизбежен
На этапе обучения различных моделей, таких как LightGBM, CatBoost, XGBoost, Neural Network, мы сталкиваемся с длинным списком гиперпараметров. Для wonder boostings мне пришлось изучать эти параметры с нуля.
Я изучала теоретическую часть деревьев StatQuest with Josh Starmer. Замечательный канал, посвященный анализу данных, всем рекомендую! В процессе работы читала описание гиперпараметра, устанавливала некое значение, думала, что понимаю, что делаю. На первом этапе результат получался плачевный: мои ожидания и реальность бежали в разных направлениях. Я корректировала свои ожидания, устанавливала новое значение гиперпараметра, снова считала. Важно при этом менять только один гиперпараметр, изменение двух и более одновременно существенно усложняет интерпретацию результата на первых порах.
В действительности я проделала прогнозов в 2-3 раза больше, чем 158. Лишь часть того, что я посчитала, я загружала для оценки на Kaggle; больше половины отметались на этапе обучения моделей. Таким образом, я вычислила 3 * 158 * 20M (обучение моделей) + 158 * 42M (прогнозирование для оценки на Kaggle) = ~16B прогнозных значений.
Такой опыт расчетов, когда на практике я начинаю понимать и даже чувствовать, как тот или иной гиперпараметр влияет на результат моделирования, называю экстенсивным. Когда решала задачу оптимизации работы ТЭЦ, то был момент, когда я с утра до вечера снова и снова оптимизировала, чтобы возникло чувство доверия к модели. Аналогичный опыт у меня был с прогнозированием, когда мне приходилось в день запускать сотню расчетов и оценивать их результаты.
Модель как машина — я должна привыкнуть к расположению ручек, усилиям для вращения руля, чувствительности педалей. Когда модель становится логичным продолжением моей мысли, как рули и педали продолжением рук и ног водителя, тогда я смогу ее эффективно применить.
Для меня важно качественно и быстро делать свою работу: работаю по 4 часа в день и стараюсь выжать максимум за это время. У экстенсивного опыта, конечно, эффективность копеечная. Вот почему для меня было важно получить такой опыт «на стороне», за рамками моих текущих проектов. Мне совесть не позволяет прийти к своему заказчику (работаю контрактником) и просить его платить мне по высокой ставке, пока я тут «поиграюсь» с моделями. Поиграюсь я сама для себя, для опыта и знаний, а уже потом продам это заказчику.
Kaggle предоставляет грандиозную площадку для приобретения важного экстенсивного опыта расчетов, без которого невозможно стать квалифицированным аналитиком.