Как развивалась наша математическая модель
Как я уже писала, работа над моделями прогнозирования началась в рамках моей трудовой деятельности в НП «АТС» — там-то я и придумала за несколько дней модель по выборке максимального подобия, которая тут же показала высокую адекватность для показателей ОРЭМ.
Далее в течение двух полных лет — с лета 2008 года по лето 2010 года — мною были разработаны десятки модернизаций модели по выборке максимального подобия (далее EMMSP). Одно из открытий состояло в том, что можно использовать EMMSP так, как она представлена в диссертации — то есть искать похожий кусочек и строить на его основании прогноз; а можно — иначе. Ниже я расскажу как.
Модификация модели прогнозирования по выборке максимального подобия
Еще в работе Бокса-Дженкинса «Анализ временных рядов: прогнозирование и управление» речь шла о том, что прогнозировать абсолютное значение временного ряда менее эффективно, чем прогнозировать возможное отклонение будущего значения от фактического. Для этого и была придумана разность d-того порядка в модели ARIMAX.
Ровно такой же ход некогда, году, наверное, в 2009, я приложила к своей модели по выборке максимального подобия. И получилось эффективно!
Модификация временных рядов для прогноза
На графике ниже представлены три временных ряда. Первый ряд (синий) — ряд цен РСВ ЕЦЗ за несколько дней; второй ряд (зеленый) — временной ряд полученный разницей соседних значений; третий ряд (коричневый) — временной ряд, полученный разницей значений со сдвигом = 24.
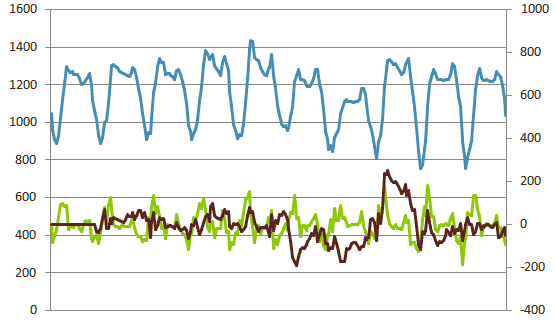
Для ясности часть значений представленных на графике временных рядов я привожу в таблице и делаю ниже к ней пояснения.
| День | Час | Исходный ряд (синий) |
Разность соседних значений (зеленый) |
Разность со сдвигом 24 (коричневый) |
|---|---|---|---|---|
| День 1 | 0 | 1046.74 | 0 | 0 |
| 1 | 962.88 | -83.86 | 0 | |
| 2 | 910.59 | -52.29 | 0 | |
| 3 | 890.47 | -20.12 | 0 | |
| ... | ... | ... | ... | |
| 23 | 1064.09 | -54.81 | 0 | |
| День 2 | 0 | 1017.02 | -47.07 | -29.72 |
| 1 | 929.05 | -87.97 | -33.83 | |
| 2 | 891.19 | -37.86 | -19.4 | |
| 3 | 918.69 | 27.5 | 28.22 | |
| ... | ... | ... | ... | |
| 23 | 1129.49 | -53.99 | 65.4 |
- Вариант 1: разность соседних значений мы получаем как 962.88 – 1046.74 = - 83.86 и т.д.
- Вариант 2: разность значений со сдвигом 24 мы получаем как 1017.02 – 1046.74 = -29.72 и т.д.
Таким образом идею формирование временного ряда разности я взяла у Бокса-Дженкинса, однако рассчитала ее двумя вариантами. Как вы понимаете, можно и третий вариант выдумать легко, например, можно брать разницу со сдвигом = 168 для временных рядов с почасовым разрешением и недельной периодичностью.
Прогноз полученного временного ряда разности
А далее я беру временной ряд разности (зеленый или коричневый) и прогнозирую его на своей модели EMMSP так, как будто это обычный ряд — и все! Выполяя такой прогноз, мы вычисляем прогноз отклонения, другими словами, прогноз изменения значений временного ряда.
Корректировка модели прогнозирования
Тут возникает один тонкий момент, который необходимо учесть при вычислении итогового абсолютного значения. Этот нюанс называется начальные значения (Initial value).
Для первого варианта расчета разницы (зеленый), когда мы вычитаем соседние значения, в качестве начального значения нам необходимо последнее фактическое значение временного ряда. Предположим, что мы прогнозируем день 2, имея фактические значения дня 1, тогда начальное значение = 1064,09 и прогноз на день 2 будет вычисляться следующим образом.
| Час | Прогноз отклонения | Прогноз абсолютного значения |
|---|---|---|
| 0 | -50 | = 1064.09 - 50 = 1014.09 |
| 1 | +25 | = 1014.09 + 25 = 1039.09 |
| 2 | -60 | = 1039.09 – 60 = 989.09 |
| 3 | ... | ... |
Для второго варианта расчета разницы, когда мы вычитаем со сдвигом 24, в качестве начального значения необходим массив фактических значений предыдущих суток. Снова предположим, что мы прогнозируем день 2, имея фактические значения дня 1, тогда выходит так.
| Час | Начальное значение | Прогноз отклонения | Прогноз абсолютного значения |
|---|---|---|---|
| 0 | 1046.74 | - 40 | = 1046.74 – 40 = 1006.74 |
| 1 | 962.88 | + 30 | = 962.88 + 30 = 992.88 |
| 2 | 910.59 | - 20 | = 910.59 – 20 = 890.59 |
| ... | ... | ... | ... |
Из таблицы ясно, что в качестве начальных значений взяты 24 фактических значения за фактический день 1.
Рекомендации и хитрости
В качестве рекомендаций замечу, что для временных рядов показателей ОРЭМ прогноз цены на электроэнергию и объемов энергопотребления оказывается в среднем точнее, если считать разность по второму варианту, то есть со сдвигом 24 значения. Этот вывод сделан на громадном числе спрогнозированных значений – более 20 000 прогнозных значений было оценено. Так что не изобретайте велосипед, а берите разность со сдвигом.
Главная хитрость состоит в том, что у нас внутри модели реализован как прогноз временного ряда разности по варианту 2, так и прогноз временного ряда абсолютных значений. Мы прогнозируем и так, и сяк, а после вычисляем консенсус-прогноз как среднее значение двух прогнозов: (1) по разности + (2) по абсолютным значениям. Такой подход и позволяет нам существенно повысить точность прогноза временных рядов показателей ОРЭМ.
На сегодняшний день наша система прогнозирования усовершенствована и в нее включена не только модель прогнозирования по выборке максимального подобия и ее модификации, а весьма хитрая модификация экспоненциального сглаживания, которая показала неожиданно для меня высокую эффективность на рядах ОРЭМ. Таким образом мы получаем консенсус-прогноз внутри нашей системы довольно сложным вариантом, но такая сложность оправдана тем, что она приводит к повышению точности прогнозирования, о которой я обязательно напишу.
Резюме
Всякая модель прогнозирования — и модель по выборке максимального подобия здесь не исключение — может быть модифицирована различными способами. Количество и качество модификаций зависит от фантазии и опыта математика — я некогда писала об этом в материале Что влияет на точность прогнозирования временного ряда?. Главной целью подобной модернизации всегда является повышение точности прогнозирования.
Часто модификация моделей прогнозирования позволяют повысить точность прогнозирования. Приведенный в настоящей записи пример модификации модели по выборке максимального подобия явился некогда качественным скачком в совершенствовании нашей автоматизированной системы прогнозирования.
Самым эффективным способом повышения точности прогнозирования, по нашему мнению, является формирование консенсус-прогноза на основании результатов прогнозирования различных моделей. В данном случае, Математическое бюро движется в разработке новых алгоритмов именно в направлении получения сложного консенсус-прогноза внутри своей автоматизированной системы прогнозирования.