В немецкой компании, в которой я работаю, решили провести конференцию по бизнес-аналитике, а точнее по анализу данных в бизнесе. Одной из тем стала тема: «Ловушки при создании моделей прогнозирования». Для подготовки темы докладчик обратился к опыту коллег и попросил тезисно описать встреченные коллегами ошибки и проблемы в области разработки моделей прогнозирования. Из результатов такого мозгового штурма был составлен доклад для конференции, анонс оригинала можно посмотреть здесь.
Из доклада и его обсуждения на конференции мы получили перечень проблем и рекомендации по их устранению.
1. Недостаточный предварительный анализ данных (data preparation)
2. Чрезмерная подгонка модели под обучающую выборку (overfitting)
3. Недоработка модели (feature design)
4. Выбор внешних факторов для модели прогнозирования (features decision)
5. Прочие ловушки
1. Недостаточный предварительный анализ данных (data preparation)
Суть проблемы
Отрезок временного ряда (выборка), с которым вы решили работать, может не отражать свойства всего временного ряда. Тогда модель, созданная на этом отрезке, будет работать только на нем и не работать на любых других участках того же временного ряда.
Решение
1.1 Общее положение
При выборе отрезка следует проверить, что данные отрезка (выборки) обладают релевантными свойствами генеральной совокупности, т.е. выбранная выборка является репрезентативной. Проверить это можно при помощи использования статистик: среднее значение, дисперсия, автокорреляционная функция и др.
1.2 Внимательное отношение к резким изменения характера временного ряда на кратких отрезках времени (выбросы и провалы)
Следует выявлять и осторожно относиться к подобным краткосрочным эффектам в данных, так как даже немногочисленные выбросы значений временного ряда могут массивно влиять на результаты моделирования. Опасные выбросы рекомендуется удалить из данных.
1.3 Внимательное отношение к пропускам значений временных рядов
Следует внимательно относиться к отсутствующим значениям в рядах данных (missing values). Пропуски могут по-разному интерпретироваться в зависимости от типа и конкретной реализации модели прогнозирования. Некоторые модели нечувствительны к «дырам» в данных, в этом случае пропуски лучше не заполнять и оставить «пустые» отметки времени. Если модель не допускает отсутствующих значений ряда, нужно заполнить их подходящим способом. При этом заполнение (интерполяция) проводится таким образом, чтобы не влиять на свойства всего временного ряда или влиять на эти свойства минимально.
2. Чрезмерная подгонка модели под обучающую выборку (overfitting)
Суть проблемы
«Переобученная» модель чрезмерно подогнана под обучающую выборку, — выборку, на которой проводится определение параметров модели или, что тоже самое, обучение модели, — и принимает случайные скачки в ней за повторяющиеся тенденции. При этом модель прогнозирования может очень плохо работать на любых новых выборках того же временного ряда, т.к. слабо воспроизводит истинные тенденции и «засоряет» их случайными скачками. Таким образом, проблема overfitting является следствием недостаточного качества модели прогнозирования, а не обучающих данных.
Аналогия overfitting – заучивание наизусть обучающих примеров.
Решение
2.1 Точно определить уровень детализации модели
Следует помнить, что сложность модели должна соответствовать сложности решаемой проблемы. Цель модели – описать основные тенденции значений временного ряда, не стремясь к абсолютно точному «угадыванию» всех значений, которое недостижимо.
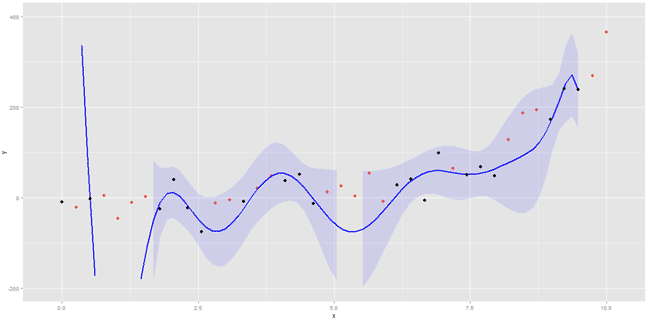
Модель на рисунке выше переобучена, т.к. проложенный полином повторяет поведение обучающих данных (черные точки), но не описывает общие закономерности генеральной совокупности (черные и красные точки).
Значительная ширина статистического разброса значений временного ряда (большая дисперсия) может являться причиной усложнения модели прогнозирования. Данные с большой дисперсией можно описать простой моделью, если она воспроизводит основные тенденции. Важно, с одной стороны, не увеличить уровень детализации модели, а с другой — дать достаточный уровень детализации для воспроизведения главных (основных) тенденций временного ряда. Равновесие в этой точки достигается за счет опыта — не следует ждать молниеносных результатов.
Формальные критерии сложности модели прогнозирования определить, к сожалению, довольно сложно, однако они могут быть интуитивно понятны специалистам. К таким критериям следует отнести:
- количество компонентов модели (например, количество регрессоров или в случае классификационно-регрессионных деревьев – максимальная длина ветви дерева);
- тип взаимосвязи между компонентами модели (аддитивная, мультипликативная);
- компоновка модели (модель данных, или модель данных + модель ошибки, или модель ошибки).
2.2 Корректное обучение модели на первом этапе
Речь идет о том, что временной ряд содержит повторяющиеся (основные) тенденции, но кроме того, в нем есть краткосрочные эффекты значений, которые, может быть, больше нигде не встретятся. Целью обучения модели прогнозирования на первом этапе является уловить основные тенденции и не углубляться в детали.
2.3 Своевременное обнаружение переобученности (overfitting)
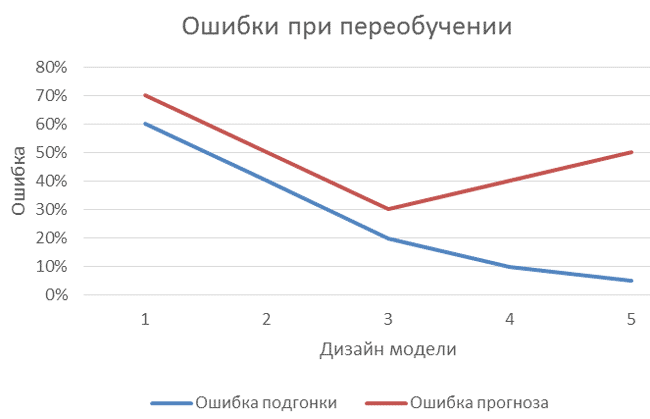
Способ обнаружить переобучение несложен: если при изменении (усложнении, добавлении глубины детализации) модели прогнозирования ошибка работы модели на обучающей выборке уменьшается (как отражено на рисунке ниже), а ошибка прогноза по контрольной выборке увеличивается, то модель «переобучена».
3. Недоработка модели (feature design)
Суть проблемы
Принцип оценки чрезмерной подгонки модели можно использовать и проводить дополнительную, более полную, проверку точности созданной модели. Игнорирование такой аналитики приводит к недостаточно качественной оценке параметров модели.
Решение
3.1 Введение в процесс разработки модели прогнозирования перекрестной проверки (cross validation)
При работе над моделью полезно делать дополнительную проверку. Обычно проверка качества модели состоит из следующих этапов:
- разбиение данных на обучающую и контрольную выборку;
- оценка модели на обучающей выборке;
- применение модели к контрольной выборке и вычисление по ней ошибки прогноза.
При добавлении перекрестной проверки эти три шага повторяются несколько раз. Каждый раз исходные данные делятся на обучающую и контрольную выборку по-разному, модель оценивается заново и по ней вычисляется ошибка прогноза. При этом формируется более качественное понятие об ошибке прогноза: она оценивается не по одному участку временного ряда, а по нескольким.
Мы проводим моделирование с помощью дерева принятия решений (CART) и хотим выяснить, какова наилучшая глубина дерева (максимальное количество вопросов для принятия решения). Для этого мы используем описанную выше перекрестную проверку с пятью прогонами. Результаты показаны на графике ниже.
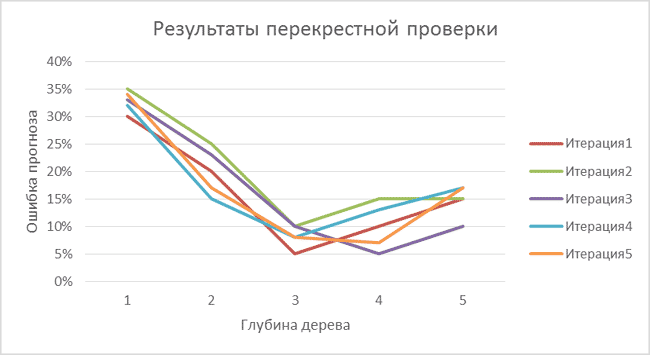
В нашем примере три прогона модели показали, что наилучшая глубина дерева — три (итерации 1, 2 и 4), т.е. достаточно трёх вопросов, чтобы принять решение. Два прогона показали, что нужны все же 4 вопроса (глубина дерева равна четырем на итерациях 3 и 5). Таким образом, мы получили пять точек зрения на ошибку прогноза и, соответственно, на оптимальную глубину дерева, которая позволит нам минимизировать ошибку. Три из них говорят в пользу глубины равной трем вопросам, и две — в пользу глубины в четыре вопроса. И для конечной модели мы выбираем дерево решений с тремя вопросами.
Какие вопросы попадут в конечное дерево решений, будет ли это комбинация из прогонов 1, 2 и 4 или только один из них, — не относится к теме перекрестной проверки. Важно понимать, что данная проверка не определяет параметров модели, а лишь даёт оценку точности выбранной модели.
4. Выбор внешних факторов для модели прогнозирования (features decision)
Суть проблемы
Многие математические модели позволяют учет внешних факторов, то есть процессов, проистекающих параллельно с исследуемым процессом, и влияющих на него. Тогда учет значений этих влияющих процессов (внешних факторов, объясняющих переменных — названий много) позволяет повысить точность прогнозирования. Проблема в выборе этих факторов.
Например, не включение дня недели в модель для прогноза потребления электроэнергии приносит больший ущерб качеству прогноза, чем выбор между деревом решений (CART) и кластерным анализом в качестве прогнозной модели (данные взяты из выполненного проекта).
| Модель | CART | CART без дня недели | Кластерный анализ |
|---|---|---|---|
| Ошибка прогноза | 10% | 13% | 12% |
Решение
Каким образом решать задачу выбора объясняющих переменных (внешних факторов)? Мы используем интуитивный критерий значимости объясняющих переменных: их значения изменяются при изменении значения исходного временного ряда и не изменяются при его постоянных значениях.
Следует помнить, что выбор типа внешних (объясняющих) факторов имеет значение: метрические факторы открывают больше возможностей для моделирования, чем категориальные.
Значениями метрических внешних факторов являются числа (например: 500; 3,14; 5,6666), их важное свойство: можно сравнивать (500 > 3,14) и трансформировать (500 + 1 = 501; 500 / 2 = 250).
Категориальные внешние факторы определяют принадлежность к группе (например, мужчина или женщина) и представляются текстом или номером категории. Некоторые факторы можно представить как метрическими, так и категориальными значениями. Например, дата может быть записана как идентификатор дня (категориальный фактор в виде текста или дня недели) или как количество дней с определенного момента времени (метрический фактор в виде числа).
В наших проектах по разработке моделей прогнозирования выходило, что метрическое представление (число) работает лучше.
Кроме того, не следует сравнивать яблоки и говядину: помните про нормирование данных.
5. Прочие ловушки
5.1 Недостаточное сотрудничество внутри команды проекта, например, непонимание между математиком, экспертом по предметной области и разработчиком ПО.
Решение лежит в сфере компетенции руководителя проекта, который должен собрать дееспособную команду.
5.2 Низкая интерпретируемость как модели, так и результата: иногда выбор модели прогнозирования не соответствует запросам клиента, потому как клиенту процесс получения прогноза совершенно не понятен. Если клиенту важно самостоятельно понимать прогнозную модель, то создание разработчиками «черного ящика» его не удовлетворит, даже если при этом будет достигнута высокая точность прогноза.
Решение данной проблемы лежит в современных графических инструментах прогнозирования, а также в области моделей прогнозирования на основе data mining — то есть анализ, который можно пояснить словами.
5.3 «Модельная религиозность» — убежденное предпочтение специалистов одной модели другим без сравнения альтернатив.
Решению данной проблемы помогает свежий взгляд со стороны, обмен точками зрения, мозговой штурм и другие креативные техники.